
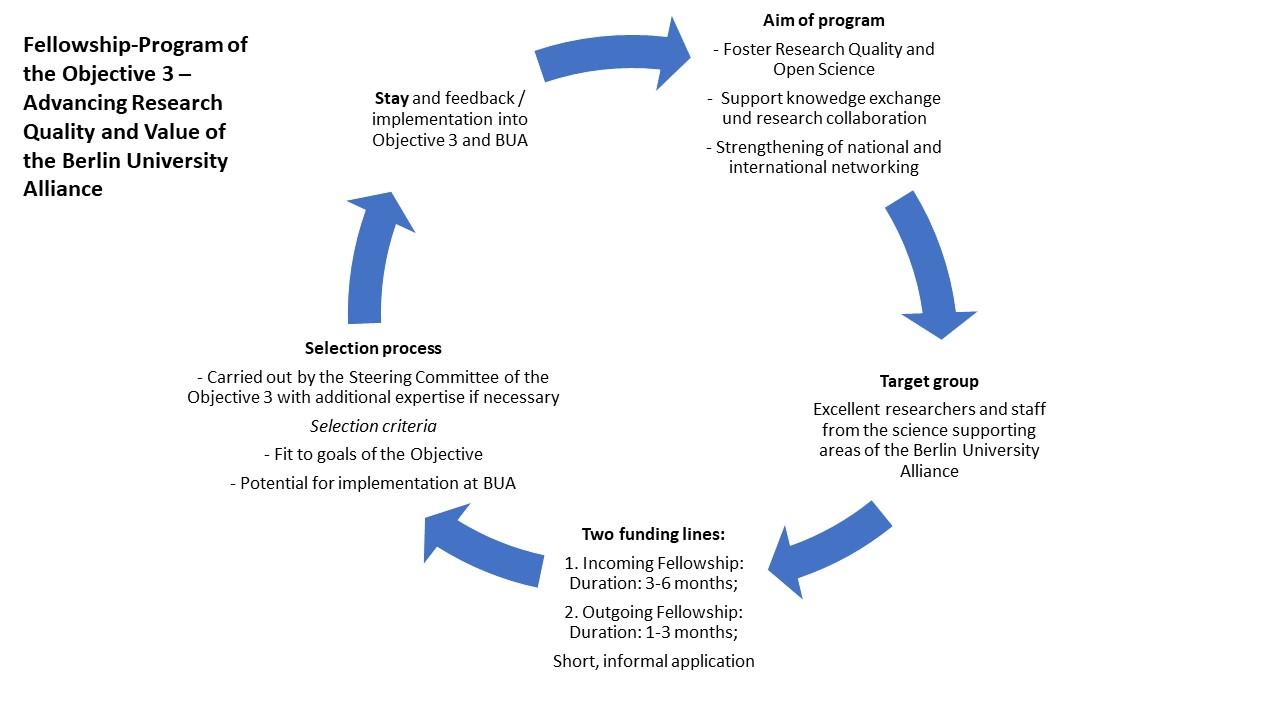
In my PhD research, I investigate how metadata for research data are generated and maintained. I have started by analyzing how metadata records of the DOI registration agency DataCite change over time (Strecker 2024a, 2024b). Recently, I was awarded a grant by the Berlin University Alliance (BUA) - through the BUA Fellowship Program of the Objective 3 - Advancing Research Quality and Value. This grant will allow me to visit Stefanie Haustein, associate professor at the School of Information Studies at the University of Ottawa and co-director of the ScholCommLab. During my stay, I will investigate metadata flows in the context of research data. In particular, I will examine the transfer of metadata from local to global contexts.
Metadata flows in the context of research data
Research data are typically deposited in research data repositories - infrastructures that specialize in handling this resource type. Metadata describing the datasets are also generated and maintained at these infrastructures. Numerous standards - metadata schemas - are used to describe research data (Asok et al. 2024; Koshoffer et al. 2018). Even within a discipline, the use of metadata schemas is not uniform (Mayernik and Liapich 2022). This variance arises because research data repositories create metadata for different use cases. On the one hand, metadata are needed to describe research data in a general and homogeneous way - for example, to enable data discovery in large search services. On the other hand, researchers need subject-specific metadata in order to be able to make an informed decision about whether they want to reuse a dataset (De Vries et al. 2022; Doran, Edmond, and Nugent-Folan 2021; Sostek et al. 2024). In order to cover this range of requirements, many research data repositories use several metadata schemas in parallel, e.g. the general DataCite metadata schema for DOI registration and a specialized schema adressing the needs of local users (Habermann 2023; Lee and Jeng 2019; Wu et al. 2023). In research data repositories, metadata are often initially generated based on a locally implemented, specific metadata schema. Metadata are then mapped to a general schema to meet global requirements such as DOI registration or harvesting (Habermann 2023). During these mapping processes, however, information from the original comprehensive description can be lost (Radio et al. 2017; Taylor et al. 2022). As a result, metadata lose completeness when they are transferred from local to global contexts (Mayernik and Liapich 2022).
During the fellowship, I will investigate metadata flows from research data repositories to DataCite. The aim is to determine whether information that is missing in DataCite metadata are also missing in local contexts or would be available but are not transmitted.
Why this matters
Complete metadata are necessary to convey the context of research data. This is relevant for many interactions with research data, including discovery, reuse and citation. Bibliometric research in particular is hindered by incomplete metadata, as is the development of metrics that are intended to reflect the impact of research data (Ninkov et al. 2021). This research will assess the potential of an approach to improve metadata quality - the optimization of mappings to the DataCite metadata schema.
Further information about our research group can be found on our official website.
This text – excluding quotes and otherwise labelled parts – is licensed under the CC BY 4.0 DEED.
References
Citation
@online{strecker2025,
author = {Strecker, Dorothea},
title = {BUA Fellowship: {Metadata} Flows in the Context of Research
Data},
date = {2025-07-18},
url = {https://doi.org/10.59350/wwwj7-4cm07},
langid = {en}
}